업무 스트레스로 쓰는 글이 절대 아닙니다.
나는 어떤 역할을 맡았는가?
저는 고객사의 플랫폼을 개발하는 프로젝트에서 (ML 파이프라인 초기 단계인) “데이터 수집 및 집계”를 담당하고 있습니다. 구체적으로는 DataStage라는 ETL 솔루션을 사용해, 머신러닝 모델에게 먹일 데이터를 만들고 실제 서비스 운영을 위해 데이터 흐름을 설계하는 역할을 맡고 있습니다.
일반적으로 머신러닝 알고리즘을 배울 때 거치는 일련의 과정과 달리, 실제 서비스 운영을 위해서는 더 다양한 요소들이 고려돼야 합니다. 예를 들어, 언제 모델을 주기적으로 업데이트할지, 모델의 예측 결과를 어떻게 이용하고 보여줄 것인지 등에 대한 요건들이 있습니다. 그중에서도 머신러닝 모델에게 전달해줄 데이터를 준비하는 일은 가장 초기에 하는 작업이라고 볼 수 있습니다.
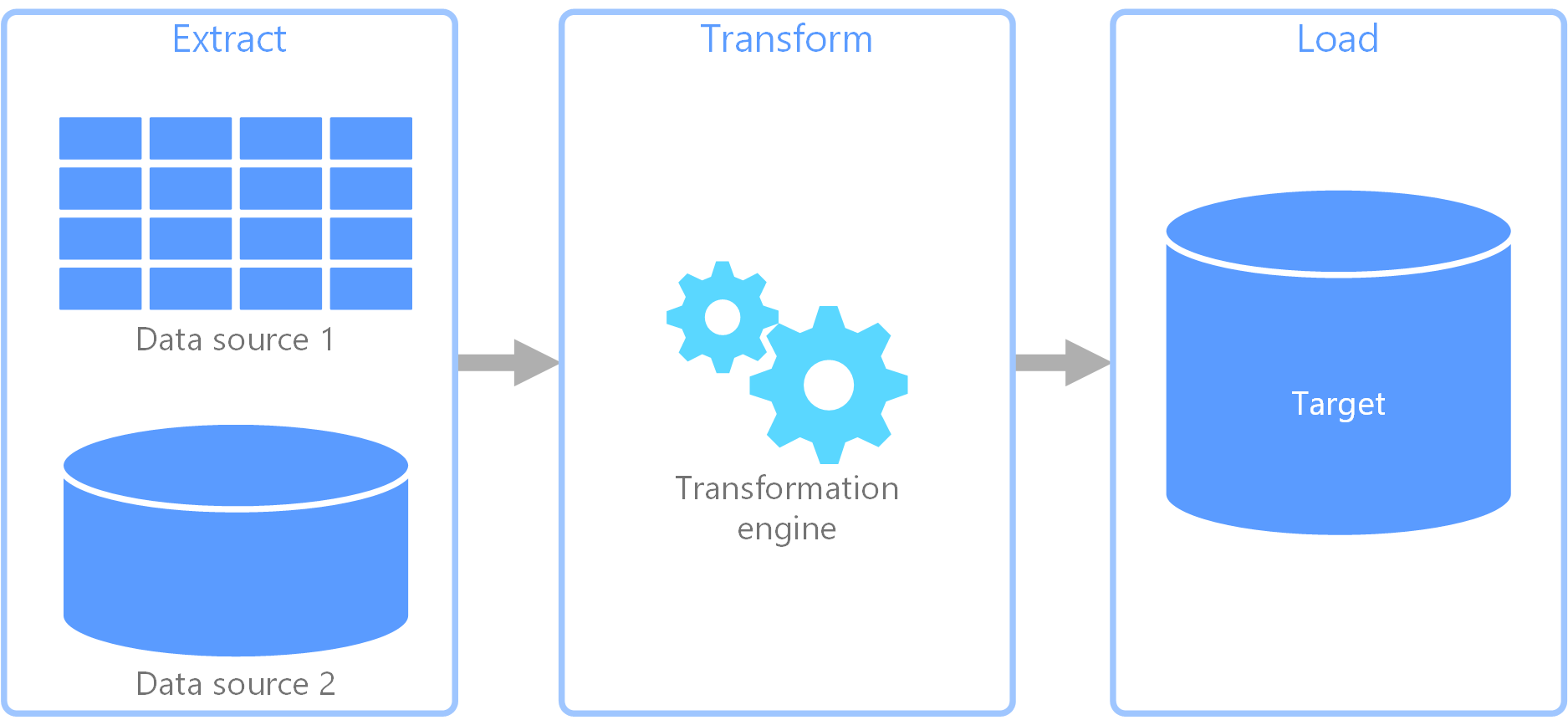
결국 기존 시스템에 존재하는 데이터는 ETL이라는 과정을 거쳐 머신러닝 파이프라인에 녹아들어 가게 됩니다. ETL은 Extract(추출) - Transform(변형) - Load(적재)의 약자로, “한 곳에 저장된 데이터(소스)를 필요에 의해 다른 곳(타겟)으로 이동시키는 것”을 말합니다. 이를 잘 다루기 위해 airflow나 kuberflow 등과 같은 오픈소스를 사용할 수도 있지만, 저는 IBM의 ETL 솔루션인 DataStage라는 툴을 사용했습니다.
정리하자면, 제 업무 역할은 크게 다음과 같습니다.
![]() 집계 테이블 생성 및 관리
집계 테이블 생성 및 관리
![]() ETL 개발 및 스케쥴링 설계
ETL 개발 및 스케쥴링 설계
![]() 각종 문서 작업
각종 문서 작업
간편화시킬 수 있는 업무 포인트 찾기
데이터 수집 및 집계 업무를 하다 보니, 수많은 파일이나 테이블에 대해 꽤 반복적이고 단순한 작업을 할 때가 있었습니다. 예를 들면, “집계 쿼리에 사용된 테이블 리스트를 추출해주세요!”, “사용된 컬럼이 개발/운영 환경 둘 다 존재하는지 궁금해요!”, “쿼리 파일 주석 변경이 필요해요!” 등이 있습니다. 300개가 넘는 집계 쿼리 파일과 테이블들을 관리하며 발생하는 단순 업무를 “파이썬 코딩으로 빠르게 간편화할 수 있지 않을까?”라는 생각을 했습니다.
먼저, 간편화할 수 있는 업무 포인트를 크게 2가지로 분류해볼 수 있었습니다.
1) DB 접속 후 정보 추출
- DB 접속하여 추출한 정보를 쉽게 전처리 할 수 있다면?
2) 집계 쿼리 파일들 관리 및 정보 추출
- 하나의 집계 쿼리 파일를 하나의 클래스 인스턴스 형태로 관리한다면?
- 각 인스턴스에 여러 함수를 달아준다면?
여기에 익숙한pandas를 결합해 프로그래밍한다면, ![]()
“단순 반복하지 않아도 일괄 처리할 수 있겠다!”라는 생각을 했습니다.
참고로 집계 쿼리 파일들은 다음과 같은 형태를 띠고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*-------------------------------------
1. 집계파일명 : J_TB_FEATURE_temp1.SQL
2. 작성자 : A.B.C
3. 소스테이블 : my_schema.TB_DATA1, your_schema.TB_DATA2
4. 타겟테이블 : my_schema.TB_FEATURE_temp1
5. ...
6. ...
-------------------------------------*/
SELECT T1.pk_1
, T1.feature1
, T2.feature2
FROM my_schema.TB_DATA1 T1
JOIN your_schema.TB_DATA2 T2
ON T1.pk_1 = T2.pk_2
;
- 주석 + 쿼리로 구성
- 주석 : 집계 파일명과 작성자, 소스/타겟 테이블 등에 대한 정보가 담겨 있음
- 쿼리 : 거의 SELECT 문임
코드 설계
앞에서 찾은 간편화 포인트를 기반으로 코드를 설계를 시작했습니다.
크게 1) DB 접속과 2) 파일 정보 추출로 나누었습니다.
1) DB 접속
크게 redshift, mysql 두 가지 버전으로 코드를 작성했고, 운영/개발에 대한 접속 정보도 저장하고 사용했습니다.
-
psycopg2,pymysql사용
[redshift]
1
2
3
4
5
6
7
8
9
import psycopg2
conn = psycopg2.connect("접속정보 입력")
cursor = conn.cursor()
sql = "실행할 SQL문장"
cursor.execute(sql)
result = cursor.fetchall()
conn.close()
[mysql]
1
2
3
4
5
6
7
8
9
import pymysql
conn = pymysql.connect("접속정보 입력")
cursor = conn.cursor()
sql = "실행할 SQL문장"
cursor.execute(sql)
result = cursor.fetchall()
conn.close()
2) SQL 파일 정보 추출
- SQL 파일들이 하나의 객체가 되어 정보를 담고 있는 구조를 떠올림 -> class 설계
- SQL 파일들을 읽고, 포함된 스키마를 찾고 등의 내용 -> class의 attribute로서 설계
- 일단, 이렇게 기본 정보와 여러 가지 메소드만 담고 있게 만든 다음에 이후 작업은 jupyter notebook에서 계속 추가하면서 작업을 실시하였음
[helper function 정의] (파일 탐색)
1
2
3
4
5
6
7
8
9
10
11
def file_search(path, style):
# style 예시 : '.SQL', '.txt'
filelist = []
for (path, dir, files) in os.walk(path):
for filename in files:
ext = os.path.splitext(filename)[-1] # 확장자 추출
if ext == style: # 확장자 비교
file = "%s/%s" % (path, filename)
filelist.append(file)
return filelist
- 해당 디렉토리의 존재하는 최종 파일경로를 가져옴 ex) C:/MyDrive/SQL/J_TB_FEATURE_temp1.SQL
-
style: 확장자를 구분하여 접근하는 용도
[class 정의]
1
2
3
class SQLfile():
def __init__(self, filepath):
self.filepath = filepath
[class method 정의]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class SQLfile():
def __init__(...):
self.filepath = filepath
def read_query(self):
# 코드 생략
return text
def extract_info(self):
# 코드 생략
return dataframe
def extract_relation(self):
# 코드 생략
return dataframe
-
read_query(): 파일 쿼리 부분을 텍스트로 읽어옴 -
extract_info(): 파일 주석 부분에서 정보를 추출함 -
extract_relation(): 파일 집계 부분에서 사용된 소스 테이블을 추출함 (주석 부분에도 있지만, 정확하게 작성하지 않은 경우가 있음)
[main 함수 정의]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def main():
# path 읽어오기
MY_PATH = 'C:/MyDrive/SQL/'
sqlfile_list = file_search(path=MY_PATH, style='.SQL')
# 각 SQL 파일마다 작업 수행
o1, o2, o3 = [], [], []
for file_path in sqlfile_list:
sqlf = SQLfile(file_path)
o1 = o1.append(sqlf.read_query())
o2 = o2.append(sqlf.extract_info())
o3 = o3.append(sqlf.extract_relation())
return sqlfile_list, o1, o2, o3
실제 업무에 사용해보기
파랑색 부분 : 미리 작성해둔 코드
초록색 부분 : 작업마다 추가한 코드 (10분 이내로 작성)
요청 1) 운영 DB와 개발 DB 테이블 정보 서로 비교해줘~
DB 접속 후 쿼리 조회(=테이블 정보 조회) → pandas 이용해서 비교
실제 사용된 코드
1
2
3
4
5
6
7
8
9
10
11
12
# redshift의 information_schema를 이용해 개발/운영에서 테이블/컬럼 목록을 추출
# 각각 dev_tables, op_tables로 저장 (dataframe 형태)
dev_tables_set = set(dev_tables['tb'].values)
op_tables_set = set(op_tables['tb'].values)
# 개발/운영 테이블 비교
for tb in dev_tables_set.difference(op_tables_set):
print(tb.upper())
for tb in op_tables_set.difference(dev_tables_set):
print(tb.upper())
1
2
3
4
5
6
7
8
9
# 개발/운영 컬럼 수 비교
# devdf, opdf는 Index가 테이블명
devdf = pd.DataFrame(devnum, devtbs, columns = ['devnum'])
opdf = pd.DataFrame(opnum, optbs, columns = ['opnum'])
totdf_comm = devdf.join(opdf, how='inner')
for idx in totdf_comm[totdf_comm['devnum'] != totdf_comm['opnum']].index:
print(idx.upper())
요청 2) SQL 파일 내 쿼리에 사용된 소스 테이블 찾아서 우리 스키마 쪽 권한 부여해줘~
SQL 파일 검색 → 쿼리 내용에 존재하는 소스 테이블 찾기 → grant 문 생성
실제 사용된 코드
1
2
3
4
5
6
7
8
9
10
11
def generate_grant_qurey(tables, grantee, privilege_type):
queries = []
for table in tables:
query = 'GRANT' + privilege_type + ' ON TABLE ' + tb + 'TO' + grantee + ';'
queries.append(query)
return queries
_, _, _, relation = main()
my_queries = generate_grant_querys(tables=relation['src_tb'].values,
grantee='my_schema',
privilege_type='SELECT')
요청 3) SQL 파일 내 쿼리 주석 좀 수정해줘~
SQL 파일 검색 → 주석 내용을 내용 찾기 → 내용 수정 → 바뀐 내용 저장하기
실제 사용된 코드
1
2
3
4
5
6
7
8
9
10
11
12
def modify_txt(txt):
# modification procedure
return new_txt
def write_txt(fname, txt):
return "finished"
files, txts, _, _ = main()
for f, t in zip(files, txts):
t2 = modify_txt(t)
f2 = f.replace("C:/MyDrive/SQL/", "C:/MyDrive/SQL_new/")
write_txt(fname=f2, txt=t2)
이 밖에도 메타정보가 바뀌어 특정 컬럼 명을 바꿔야 하는 경우, 특정 스키마 명이 포함된 테이블을 찾는 경우 등 다양한 요청이 있을 때마다 조금씩 변형해가며 유용하게 쓸 수 있었습니다.
기타 유용하게 썼던 것들
엑셀(Excel)
-
VLOOKUP함수 -
데이터 > 텍스트 나누기기능 -
LEFT,RIGHT,LEN등
명령 프롬프트(CMD)
1) CMD로 폴더 내 파일명 리스트 추출
-
cd명령어로 원하는 디렉토리로 이동 -
dir/b > file_list.txt입력
2) CMD로 확장자 일괄 변경
ren *.txt *.sql
기타 파이썬 라이브러리
-
paramiko,ftplib: ftp 접속해서 파일 접근할 때 사용
기타 프로그램
-
SharpKeys: ctrl+c/v 위치를 변경하기 위해 사용 (F1,F2,F3 조합) -
LTFViewer: 대용량 파일 뷰어 (대량 로그 데이터 상태 확인) -
GSplit 3: 대용량 파일 나누고 합치는 프로그램
스스로 피드백하기
느낀 점 & 아쉬운 점
-
pandas는 굉장히 유용했습니다!- 엑셀 시트 함수를 사용하는 것보다,
pandas로 처리하는 속도가 이제는 더 빠릅니다. - csv 형태의 자료를 다루는 부서에서
pandas로 간편화한다면, 불필요한 업무를 많이 줄일 수 있지 않을까요?
- 엑셀 시트 함수를 사용하는 것보다,
- 손수 작업하는 시간과 코드 설계 및 작성, 실행 시간을 서로 비교했을 때, 파이썬 간편화가 훨씬 빠른 속도로 처리했다는 것을 확인했습니다.
- 고객사의 DRM이 걸려 있어 다양한 자동화를 시도하지 못했습니다.
-
SQL파일을 처음 작성할 때 메타정보처럼 구조에 맞추어 (겁나 고생하며) 작성하니, 나중에pandas로 읽어와 처리하기 정말 편했습니다. - SI 프로젝트에서 다들 개발하기 급급하다 보니, 피드백이 없이 결과를 찍어내는 느낌을 받았습니다.
- ETL은 솔루션보다 오픈소스를 사용해 개발하고 싶었습니다...
- 개발에 관해 공부해본 적이 없기 때문에, 올바른 방향으로 접근하며 “간편화”를 달성했는지는 잘 모르겠습니다

- 그래도 “업무를 하며 유용했는가?”에 대한 질문의 답으로는 “Yes”입니다.

마무리
작년 10월부터 올해 4월 중순까지 있던 플랫폼 개발 프로젝트도 곧 끝이 납니다. 데이터 수집 및 집계라는 업무의 큰 틀을 배울 수 있었고, 실제 서비스를 운용하는데 부딪칠 수 있는 점들과 SI 개발을 할 때 중요한 점에 대해서도 배울 수 있었습니다. 다만, 일하는 방식과 사람에 대해 회의감이 많이 든 프로젝트였고 저에게 어떤 것들이 더 적합한지 많이 고민하게 해준 시간이었습니다.