
딥러닝에서 등장하는 지식 증류(Knowledge Distillation)에 대해 간략히 소개하는 글입니다.
지식(Knowledge) + 증류(Distillation)
국립국어원의 표준국어대사전에 따르면, 지식과 증류라는 단어를 다음과 같이 정의하고 있습니다.
지식: 어떤 대상에 대하여 배우거나 실천을 통하여 알게 된 명확한 인식이나 이해증류: 액체를 가열하여 생긴 기체를 냉각하여 다시 액체로 만드는 일. 여러 성분이 섞인 혼합 용액으로부터 끓는점의 차이를 이용하여 각 성분을 분리할 수 있다.

그렇다면, 딥러닝의 세계에서 “지식을 증류한다”라는 말은 어떤 뜻일까요? 딥러닝 모델에 대한 이해가 어느 정도 있는 분은 “아! 학습된 모델로부터 지식을 추출하는 건가?”라고 바로 유추할 수 있을 것 같습니다. 그렇다면, 이렇게 추출한 지식을 활용할 수 있지 않을까요?
결국 딥러닝에서 지식 증류는 큰 모델(Teacher Network)로부터 증류한 지식을 작은 모델(Student Network)로 transfer하는 일련의 과정이라고 할 수 있습니다. 오늘은 크게 3가지 질문에 대한 답을 살펴보고, 딥러닝에서 자주 사용되는 용어 Knowledge Distillation에 대해 친숙해져 보려고 합니다.
- Q1. Knowledge Distillation은 도대체 왜 등장했을까?
- Q2. Knowledge Distillation은 언제 처음으로 등장했을까?
- Q3. Knowledge Distillation은 어떻게 하는 걸까?
Q1. Knowledge Distillation은 도대체 왜 등장했을까?
지식 증류를 처음으로 소개한 논문은 모델 배포(model deployment) 측면에서 지식 증류의 필요성을 찾고 있습니다.
우리가 딥러닝을 활용해 인공지능 예측 서비스를 만든다고 가정해봅시다. 연구 및 개발을 통해 만들어진 딥러닝 모델은 다량의 데이터와 복잡한 모델을 구성하여 최고의 정확도를 내도록 설계되었을 것입니다. 하지만 모델을 실제 서비스로 배포한다고 생각했을 때, 이 복잡한 모델은 사용자들에게 적합하지 않을 수 있습니다. 아래 슬라이드처럼 모델이 배포된 모바일 장치는 (복잡한 모델이 작동하는데 필요한) 강력한 하드웨어가 아니기 때문입니다.
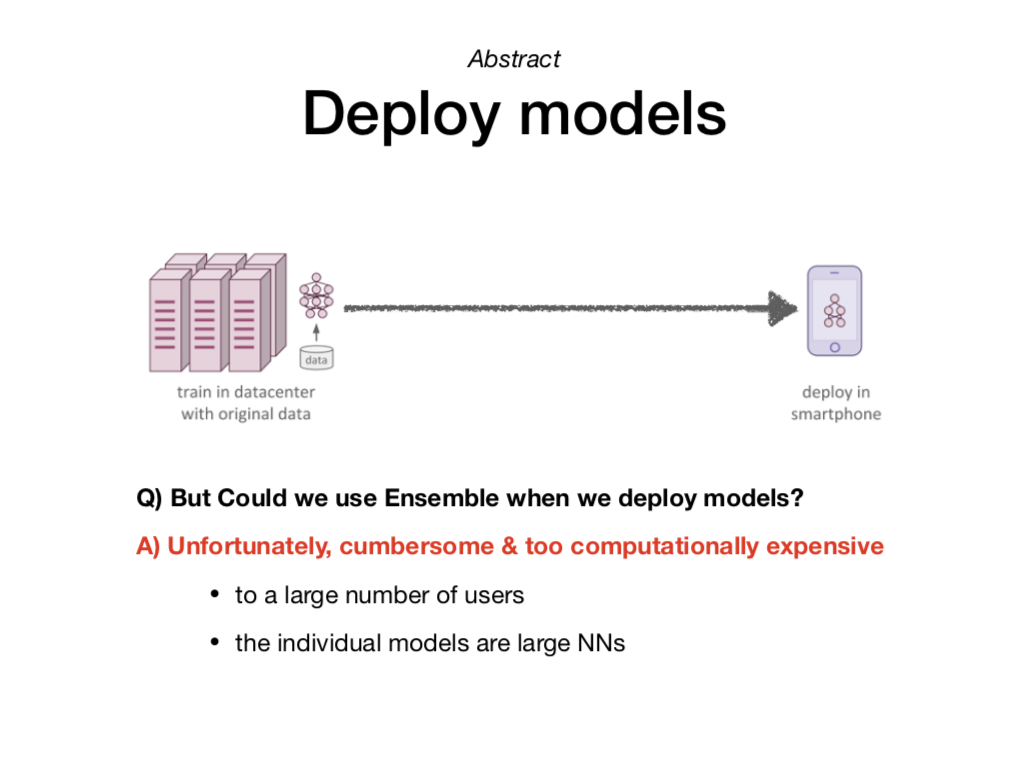
그렇다면 다음의 두 모델이 있다면 어떤 모델을 사용하는 게 적합할까요?
- 복잡한 모델 T : 예측 정확도 99% + 예측 소요 시간 3시간
- 단순한 모델 S : 예측 정확도 90% + 예측 소요 시간 3분
어떤 서비스냐에 따라 다를 수 있겠지만, 배포 관점에서는 단순한 모델 S가 조금 더 적합한 것으로 보입니다.
그렇다면, 복잡한 모델 T와 단순한 모델 S를 잘 활용하는 방법도 있지 않을까요? 바로 여기서 탄생한 개념이 지식 증류(Knowledge Distillation)입니다. 특히, 복잡한 모델이 학습한 generalization 능력을 단순한 모델 S에 전달(transfer)해주는 것을 말합니다.
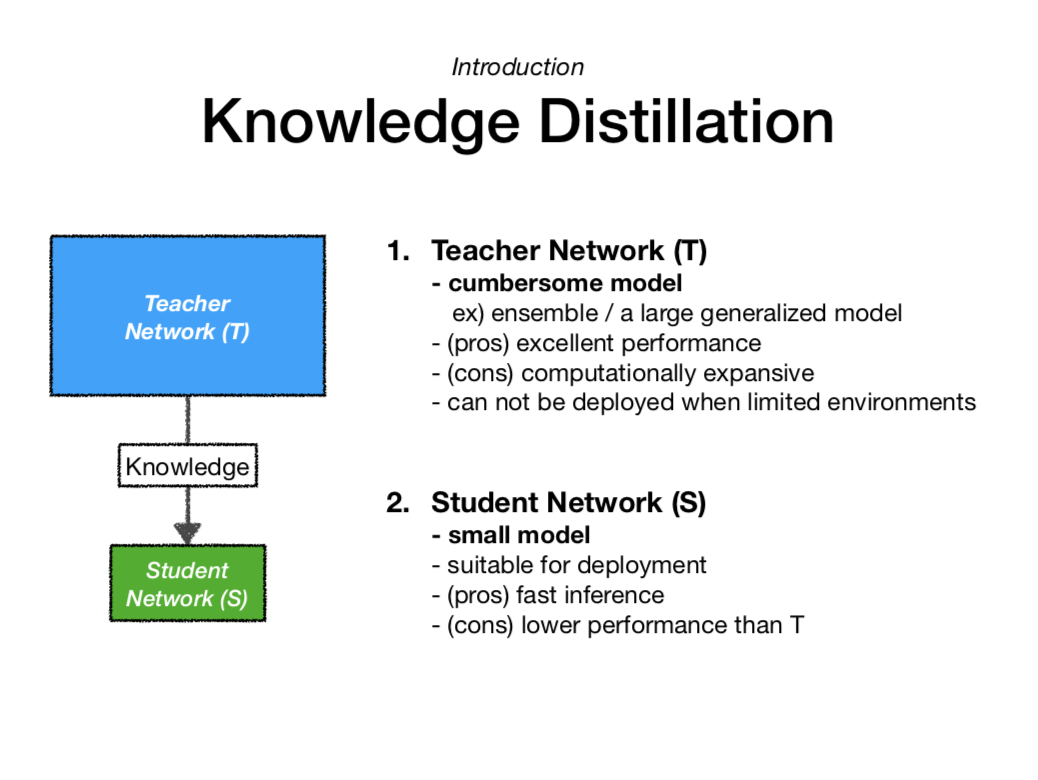
위 슬라이드는 복잡한 모델 T와 단순한 모델 S가 가지는 특징에 관해 설명하고 있습니다.
이 개념을 처음으로 제시한 논문에서는 복잡한 모델을 cumbersome model로, 단순한 모델을 simple model로 나누어 설명하고 있습니다. 하지만 이후 등장하는 논문에서는 일반적으로 Teacher model과 Student model로 표현하고 있습니다. 먼저 배워서 나중에 지식을 전파해주는 과정이 선생님과 학생의 관계와 비슷하여 이렇게 표현한듯합니다.
Q2. Knowledge Distillation은 언제 처음으로 등장했을까?
Knowledge Distillation은 NIPS 2014 workshop에서 발표한 논문 “Distilling the Knowledge in a Neural Network”에서 처음으로 등장한 개념입니다. 논문을 요약하자면 다음과 같습니다.
- 앙상블과 같은 복잡한 모델을 다량의 유저에게 배포하는 것은 하드웨어적으로 엄청 힘듦
- 앙상블이 가진 지식을 단일 모델로 전달해주는 기존 기법이 있으나 그보다 더 일반적인 연구를 함
- MNIST 데이터를 사용해, 큰 모델로부터 증류된 지식이 작은 모델로 잘 전달되는지 확인함
- 앙상블 학습 시간을 단축하는 새로운 방법의 앙상블을 제시함

저자 3명의 2015/01~2020/05 citation이 도합 40만이 넘는, 이 엄청난 논문은 읽기에도 부담이 없고 실험도 간단하여 쉽게 따라 해볼 수 있습니다. 아래는 Knowledge Distillation을 실험하는 간단한 implementation 링크이므로 궁금하신 분들은 참고하시면 좋을 것 같습니다.
- https://github.com/peterliht/knowledge-distillation-pytorch (pytorch)
- https://github.com/DushyantaDhyani/kdtf (tensorflow)
Q3. Knowledge Distillation은 어떻게 하는 걸까? (with Hinton’s KD)
추상적인 개념에 대해 주야장천 설명은 들었는데, 구체적인 방법론은 어떻게 하면 될까요? 어떻게 큰 모델로부터 작은 모델로 지식을 전달할 수 있는 걸까요? 이는 신경망과 손실함수를 살펴보면 쉽게 이해할 수 있습니다. 다음은 Hinton이 제시한 Knowledge Distillation을 기반으로 살펴볼 예정입니다. (classification task에 대한 기초 수식 이해가 필요한 내용입니다.)
1) Soft Label
일반적으로, 이미지 클래스 분류와 같은 task는 신경망의 마지막 softmax 레이어를 통해 각 클래스의 확률값을 뱉어내게 됩니다. 다음과 같은 수식을 통해 $i$번째 클래스에 대한 확률값($q_i$)를 만들어내는 방식입니다.
\[q_i = \frac{exp(z_i)}{\sum_j{exp(z_j)}}\]이를 레이블을 통해 구체적으로 살펴보겠습니다.

(↑) 기존의 개 사진의 레이블을 Original (Hard) Targets라고 생각할 수 있습니다. (Hard = discrete)

(↑) 우리가 학습한 딥러닝 모델로 어떤 사진(실제는 개)을 넣는다면 클래스마다 확률값($q$)를 출력할 것입니다. 그에 따라 가장 높은 출력값인 0.9의 클래스 “개”를 예측하게 되는 구조입니다. 이때, Hinton은 예측한 클래스 이외의 값을 주의 깊게 보았습니다. 개를 제외한 고양이나 자동차 그리고 젖소의 확률을 살펴봤다는 뜻입니다.
그렇다면 이 출력값들을 통해 무엇을 알 수 있을까요? 결론부터 말하면, 이 출력값들이 모델의 지식이 될 수 있다고 말하고 있습니다. 우리가 예측하려고 하는 이 사진이 강아지인 것은 알겠는데 자동차나 젖소보다 고양이에 더 가까운 형태를 띠고 있다는 것을 알 수 있다는 것입니다. 하지만, 이러한 값들은 softmax에 의해 너무 작아 모델에 반영하기 쉽지 않을 수 있습니다.

따라서 출력값의 분포를 좀 더 soft하게 만들면, 이 값들이 모델이 가진 지식이라고도 볼 수 있을 듯 합니다. 이것이 바로 Knowledge Distillation의 시초(Hinton’s KD)입니다. 그리고 해당 논문에서는 이러한 soft output을 dark knowledge라고 표현하고 있습니다.
\[q_i = \frac{exp(z_i/T)}{\sum_j{exp(z_j/T)}}\]soft하게 만들어주는 과정을 수식으로 표현하면, 위와 같습니다. 기존 softamx output과 다른 점은 $T$라는 값이 분모로 들어갔다는 점입니다. 본 논문에서는 온도(temperature)라고 표현하고 있고, 이 값이 높아지면 더 soft하게 낮아지면 hard하게 만드는 것을 살펴볼 수 있습니다. 결국, 이 $T$(온도)라는 설정 때문에 증류(Distillation)라는 과정이 나오게 된 것으로 볼 수 있습니다.
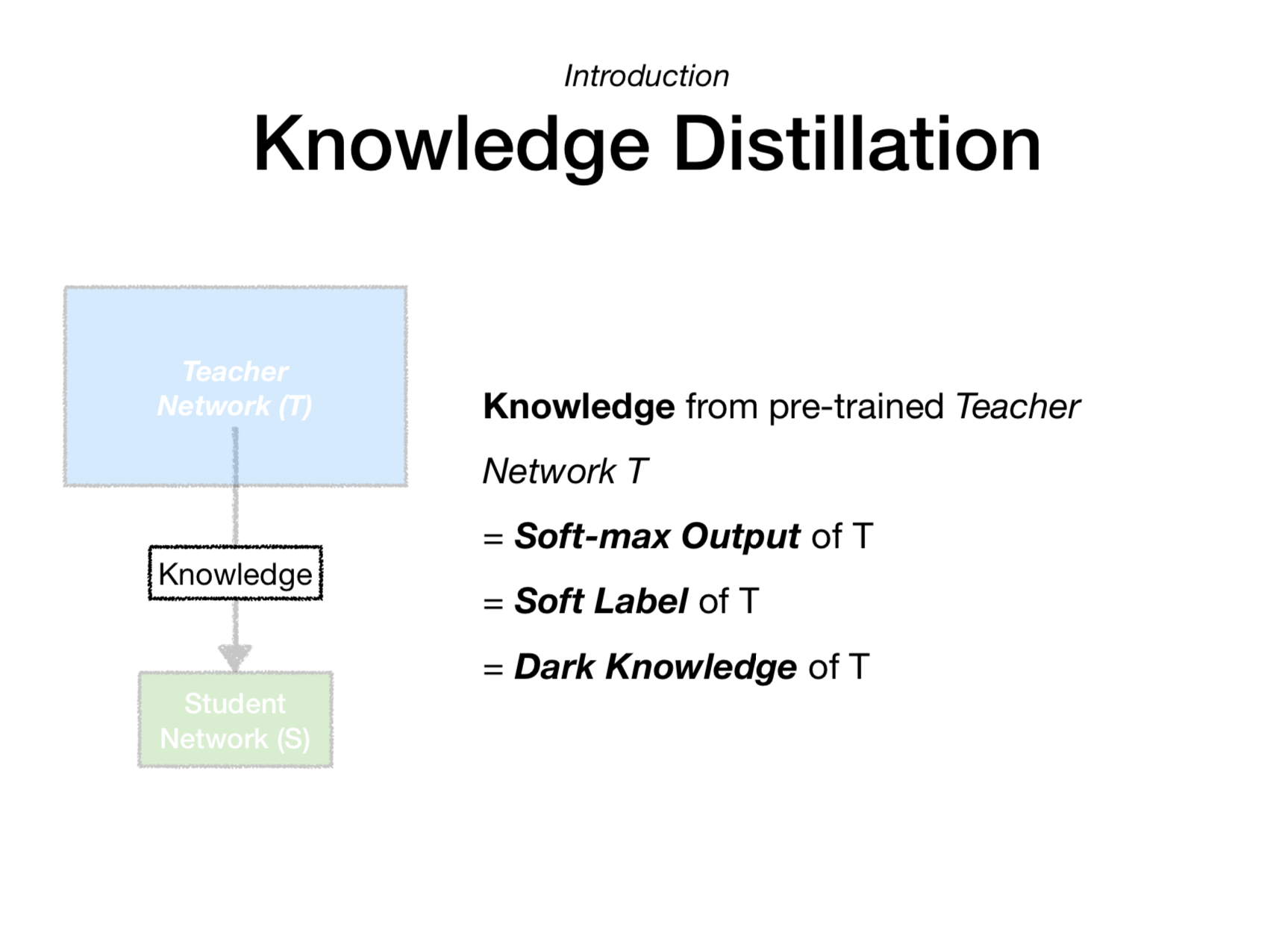
2) distillation loss
위에서 정의한 Hinton의 soft target은 결국 큰 모델(T)의 지식을 의미합니다. 그렇다면 이 지식을 어떻게 작은 모델(S)에게 넘길 수 있을까요? 먼저, 큰 모델(T)을 학습을 시킨 후 작은 모델(S)을 다음과 같은 손실함수를 통해 학습시킵니다.
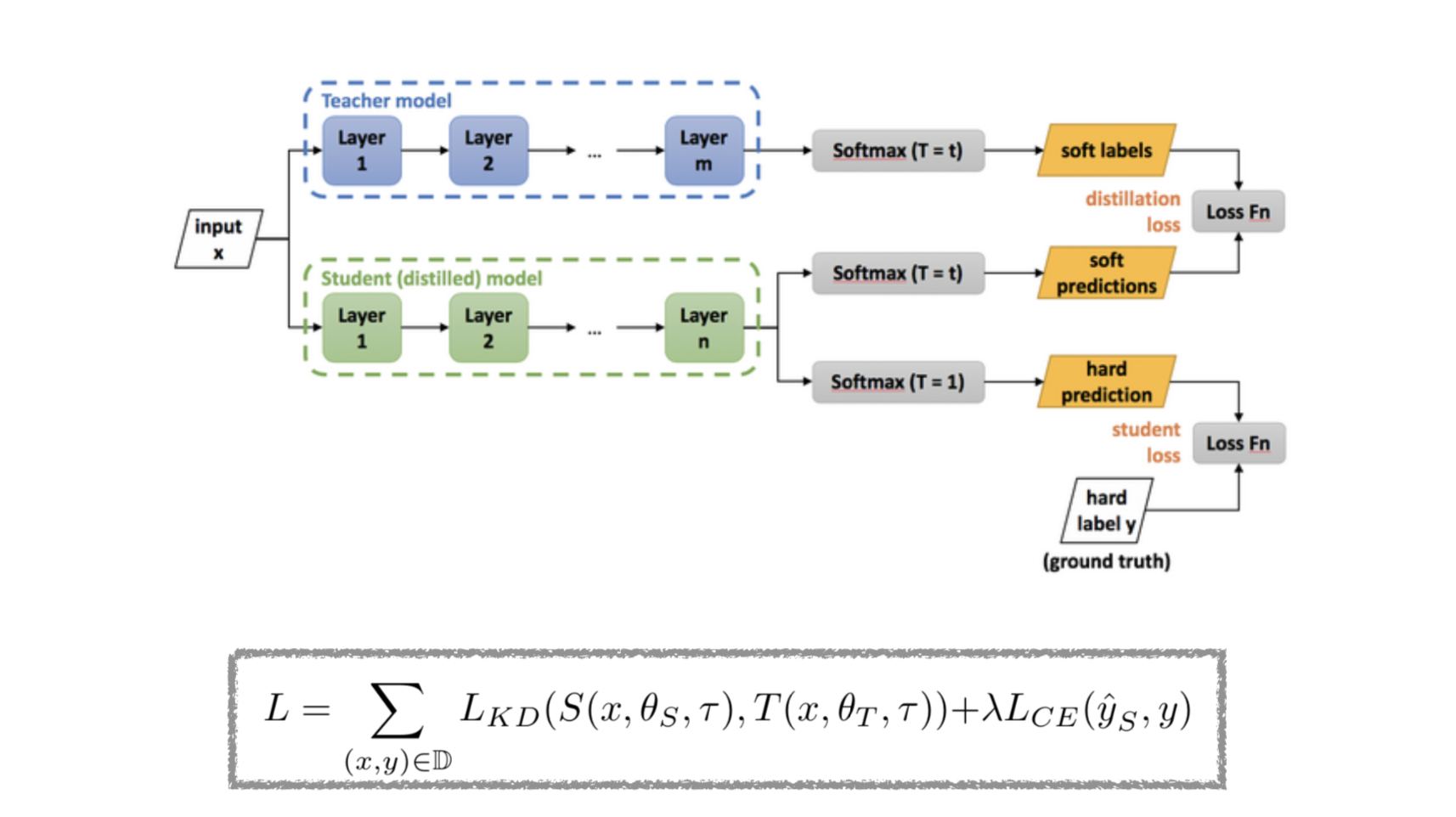
여기서 $L$은 손실함수, $S$는 Student model, $T$는 Teacher model을 의미합니다. 또한 $(x,y)$는 하나의 이미지와 그 레이블, $\theta$는 모델의 학습 파라미터, $\tau$는 temperature를 의미합니다.
위 슬라이드에서 정의하는 손실함수는 크게 기존 이미지 분류에서 사용하는 Cross Entropy Loss ($L_{CE}$)와 Distillation Loss ($L_{KD}$)로 구성되어 있습니다. $L_{KD}$는 잘 학습된 Teacher model의 soft labels와 Student model의 soft predictions를 비교하여 손실함수를 구성합니다. 이때, 온도($\tau$)는 동일하게 설정하고 Cross Entropy Loss를 사용합니다.
3) Summary
- Teacher Network 학습
- Student Network 학습
- Student Network soft prediction + Teacher Network soft label → distillation loss 구성
- Student Network (hard) prediction + Original (hard) label → classification loss 구성
ETC 그 밖에…
- knowledge transfer, knowledge distillation, transfer learning 차이는?
- Knowledge Transfer은 크게 Knowledge Distillation과 Transfer Learning으로 구분 가능
- Transfer Learning은 서로 다른 도메인에서 지식을 전달하는 방식
- Knowledge Distillation은 같은 도메인 내 모델 A에게 모델 B가 지식을 전달하는 방식 (Model Compression 효과)
- Knowledge Transfer은 크게 Knowledge Distillation과 Transfer Learning으로 구분 가능
- KD는 Model Compression이라는 측면에서 다양하게 사용할 수 있음
- BERT와 같은 무거운 모델을 경량화하기 위해 KD를 사용
- (개인적인 생각) KD의 의의는 두 가지 질문에 기초하여 생각할 수 있음
- 1) 어떤 것을 모델의 지식이라고 볼 것인가?
- 2) 정의한 모델의 지식을 어떻게 transfer할 것인가?
- 이러한 관점에서, Hinton’s KD 접근 방식은 지식을 soft label로 보고 마지막 레이어에 온도를 사용해 transfer한 것
reference
blog
- https://towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764
- https://medium.com/neuralmachine/knowledge-distillation-dc241d7c2322
- https://medium.com/analytics-vidhya/knowledge-distillation-dark-knowledge-of-neural-network-9c1dfb418e6a
- https://blog.lunit.io/2018/03/22/distilling-the-knowledge-in-a-neural-network-nips-2014-workshop/
- https://light-tree.tistory.com/196
- https://kdst.tistory.com/22
paper